Multi Agent Reinforcement Learning
사례조사
본 연구가 목표로 하고 있는 Multi Agent System를 이용한 다양한 분야의 국내외 사례를 살펴보겠다. 주로 사용할 가능성이 높은 오픈소스 라이브러리 OpenAI Gym을 중심으로 알아본다.
ETRI 2019 심층 강화학습 기술 동향
멀티 에이전트 강화학습의 어려운점
- 기존 싱글 에이저트 중심의 강화학습에서 갖고 있던 어려운 점을 똑같이 지닌다.
- 탐색-이용 딜레마 (Explore-exploit dilemma)
- 부분 관측 가능성
- 멀티 에이전트 환경이 갖는 고유의 비정상성 특성
- 에이전트들 간의 신뢰할당 문제
멀티 에이전트 강화학습 알고리즘 분류
싱글 에이전트와 마찬가지로 심층신경망을 이용한 에이전트의 정책 함수나 가치 함수를 근사하는 알고리즘들이 제안되고 있다.
최적의 행동가치 함수 (Action-value function) 학습을 목표로 하는 Q-러닝 계열과 정책함수를 경사상승법을 이용하여 직접 학습하는 정책 경사 계열로 구분할 수 있다.
대표적 최신 알고리즘
- Q-러닝 계열 : QMIX [7]
- 정책 경사 계열 : MADDPG [8]
Q-러닝 기반 MARL 알고리즘
Q-러닝은 주어진 상태에서 주어진 행동이 가져올 누적 보상의 기댓값을 예측하는 Q-함수(행동가치함수)를 벨만최적방정식을 이용하여 학습하고, 에이전트는 학습한 Q-함수의 예측값과 $\epsilon$-탐욕 정책에 따라 각 상태에서 가장 높은 가치를 주는 행동을 선택하며 환경 탐색을 이어 나가는 방식으로 실행된다.
Q-러닝 알고리즘을 이용하여 자신이 부분적으로 관측한 로컬 상황(Observation)을 기반으로 자신의 행동을 선택할 수 있는 로컬 Q-함수를 다른 에이전트에 대한 정보 없이 독립적으로 학습하는 방식을 제안하고 있다.
완전 분산형(fully decentralized) 구조
학습과 탐색을 동시에 수행하고 있는 다른 에이전트들을 환경의 일부로 간주
주에이전트 관점에서는 Q-러닝 알고리즘이 수렴하기 위한 마르코프 가정 만족 못해 학습이 어려움
비정상적(non-stationary) 환경으로 인해 DQN 알고리즘의 경우 경험 리플레이(experience replay) 메모리에 저장된 과거의 경험들을 그대로 활용하기 어렵다는 문제도 발생
완전 집중형(fully centralized) 구조 : 개선 모델
에이전트 각각의 로컬 Q-함수를 학습하는 대신, 에이전트들의 모든 로컬 관측 상황과 전역 환경 상태를 고려하여 모든 에이전트들의 공동행동(joint action)이 가져올 누적 보상 기댓값을 예측하는 한 개의 전역 Q-함수를 학습하는 방식도 가능
에이전트 수가 증가함에 따라 공동행동 공간이 기하급수적으로 증가하므로 에이전트 수에 제약이 따른다.
QMIX 알고리즘
위 두 구조의 절충안
다수의 에이전트가 각각 자신이 부분적으로 관측 : 로컬 상황에서 개별 행동의 가치를 예측해주는 로컬 Q-함수 사용
모든 로컬 Q-함수의 출력값들과 에이전트들의 개별 행동에 따른 전역 환경 상태를 모두 종합
에이전트들의 공동 행동에 대한 가치를 예측하는 전역 Q-함수를 모두 사용하는 새로운 멀티 에이전트 방식 제안
로컬 Q-함수를 근사하는 에이전트 신경망과 다른 에이전트들의 행동을 고려하는 전역 Q-함수를 근사하는 믹싱 신경망을 최적의 공동행동 학습을 목표로 종단 간(end-to-end)학습. 따라서, 기존 완전 분리형 방식보다 안정적 학습이 가능
실제로 스타2 전략게임의 멀티유닛 제어 작업에서 기존 Q-러닝 기반의 MARL 알고리즘보다 개선된 성능을 보여주고 있음
정책 경사 기반 MARL 알고리즘
정책 경사 알고리즘은 주어진 상태에서 에이전트가 해야 하는 행동을 출력하는 정책 함수를 경사 상승법으로 직접 학습하는 방식
에이전트 행동을 결정하는 정책 함수를 근사하는 정책 신경망 : Actor
정책을 평가하는 역할을 하는 가치 함수(Q-함수)를 근사하는 가치 신경망 : Critic
위의 두 신명망으로 종단 간 학습하는 액터-크리틱 알고리즘이 대표적
액터-크리틱 알고리즘을 학습으로 성공적으로 확장하기 위해서는 에이전트가 환경을 탐색하며 수집하는 경험에 따라 Q-함수의 예측값이 크게 변동하기 때문에 정책함수 학습이 느리다는 정책 경사 학습 고유의 취약점뿐만 아니라 비정상적 환경에서 수렴하기 어려운 Q-함수 학습의 문제점까지 모두 고려할 필요가 있다.
MADDPG와 M#DDPG[11] 알고리즘
최근 제안된 이 두 알고리즘은 N개의 에이전트들의 행동을 결정하는 N개의 분리된 액터(actor)와 정책 신경망 각각을 평가하는 N개의 크리틱(critic)을 경험 리플레이 메모리에 저장된 경험 데이터를 이용하여 학습하는 새로운 멀티 에이전트 학습 방식을 제안
에이전트들이 각각 다른 에이전트들이 선택한 행동들을 모두 고려하여 자신의 정책 신경망을 업데이트하는 방향을 결정하므로 비교적 안정적 학습이 가능
학습 단계 : 다른 에이전트들의 정보를 사용해야 하는 중앙집중형의 학습(Centralized learning)이 이룸
학습 완료 후 : 독립된 정책 신경망(액터)을 이용하여 로컬 관측 상태에서 최적의 행동을 선택할 수 있는 분리된 실행(Decentralized execution)이 가능
따라서, 본 알고리즘은 협업이 필요한 환경뿐만 아니라, 경쟁 환경도 우수한 성능을 보임
OpenAI Gym : Multi-Agent Particle Environment
간단하게 파티클로만 이루어진 멀티에이전트 환경 제공
물리 법칙에 따른 연속, 이산 관측 탑재
관련 논문 : Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments
환경 리스트
| Env name in code (name in paper) | Communication? | Competitive? | Notes |
|---|---|---|---|
simple.py | N | N | Single agent sees landmark position, rewarded based on how close it gets to landmark. Not a multiagent environment – used for debugging policies. |
simple_adversary.py (Physical deception) | N | Y | 1 adversary (red), N good agents (green), N landmarks (usually N=2). All agents observe position of landmarks and other agents. One landmark is the ‘target landmark’ (colored green). Good agents rewarded based on how close one of them is to the target landmark, but negatively rewarded if the adversary is close to target landmark. Adversary is rewarded based on how close it is to the target, but it doesn’t know which landmark is the target landmark. So good agents have to learn to ‘split up’ and cover all landmarks to deceive the adversary. |
simple_crypto.py (Covert communication) | Y | Y | Two good agents (alice and bob), one adversary (eve). Alice must sent a private message to bob over a public channel. Alice and bob are rewarded based on how well bob reconstructs the message, but negatively rewarded if eve can reconstruct the message. Alice and bob have a private key (randomly generated at beginning of each episode), which they must learn to use to encrypt the message. |
simple_push.py (Keep-away) | N | Y | 1 agent, 1 adversary, 1 landmark. Agent is rewarded based on distance to landmark. Adversary is rewarded if it is close to the landmark, and if the agent is far from the landmark. So the adversary learns to push agent away from the landmark. |
simple_reference.py | Y | N | 2 agents, 3 landmarks of different colors. Each agent wants to get to their target landmark, which is known only by other agent. Reward is collective. So agents have to learn to communicate the goal of the other agent, and navigate to their landmark. This is the same as the simple_speaker_listener scenario where both agents are simultaneous speakers and listeners. |
simple_speaker_listener.py (Cooperative communication) | Y | N | Same as simple_reference, except one agent is the ‘speaker’ (gray) that does not move (observes goal of other agent), and other agent is the listener (cannot speak, but must navigate to correct landmark). |
simple_spread.py (Cooperative navigation) | N | N | N agents, N landmarks. Agents are rewarded based on how far any agent is from each landmark. Agents are penalized if they collide with other agents. So, agents have to learn to cover all the landmarks while avoiding collisions. |
simple_tag.py (Predator-prey) | N | Y | Predator-prey environment. Good agents (green) are faster and want to avoid being hit by adversaries (red). Adversaries are slower and want to hit good agents. Obstacles (large black circles) block the way. |
simple_world_comm.py | Y | Y | Environment seen in the video accompanying the paper. Same as simple_tag, except (1) there is food (small blue balls) that the good agents are rewarded for being near, (2) we now have ‘forests’ that hide agents inside from being seen from outside; (3) there is a ‘leader adversary” that can see the agents at all times, and can communicate with the other adversaries to help coordinate the chase. |
{kind=link}
OpenAI : Emergent Tool Use from Multi-Agent Interaction
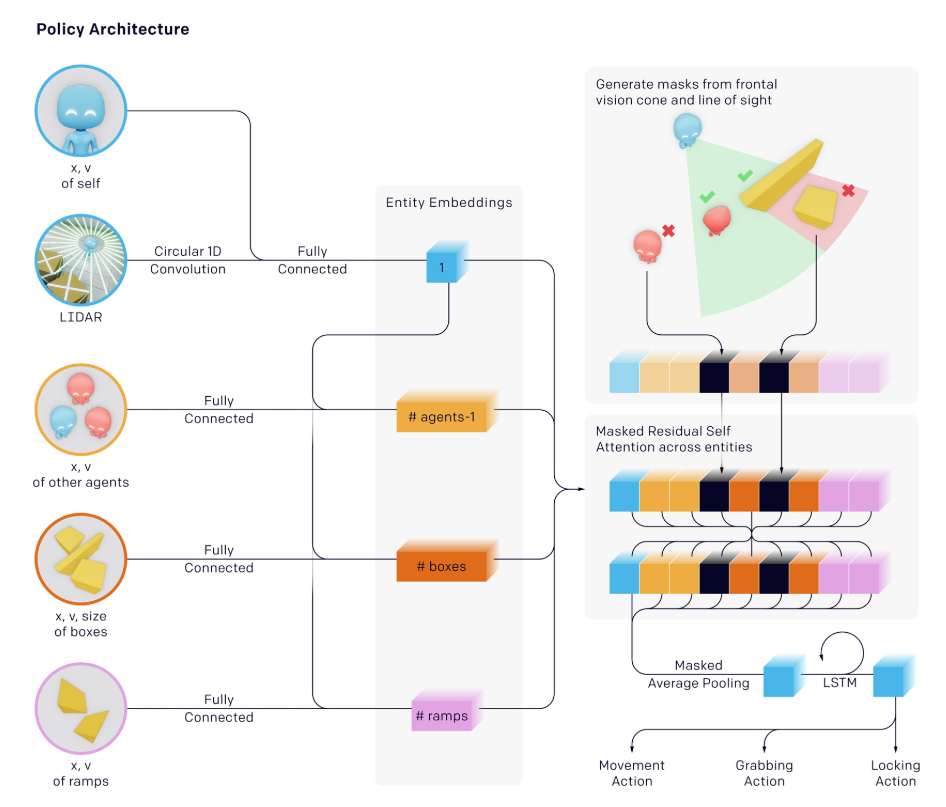
- Training hide-and-seek agents We use the same training infrastructure and algorithms used to train OpenAI Five and Dactyl. However, in our environment each agent acts independently, using its own observations and hidden memory state. Agents use an entity-centric state-based representation of the world, which is permutation invariant with respect to objects and other agents.
Each object is embedded and then passed through a masked residual self attention block, similar to those used in transformers, where the attention is over objects instead of over time. Objects that are not in line-of-sight and in front of the agent are masked out such that the agent has no information of them.
{kind=link}
여러 분야 응용
Online Distributed Resource Allocation Applying multi-agent learning on to come up with effective resource allocation in a network of computing. Zhang, Chongjie, Victor R. Lesser, and Prashant J. Shenoy. “A Multi-Agent Learning Approach to Online Distributed Resource Allocation.” IJCAI. Vol. 9. 2009.(44회 인용)
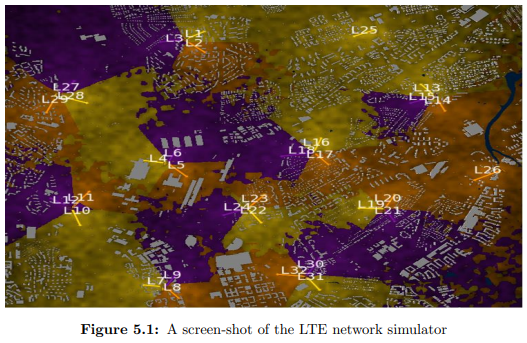
Cellular Network Optimization Applying MARL in LTE networks, guide base stations to maximise mobile service quality. Pandey, Binda. “Adaptive Learning For Mobile Network Management.” 2016. LTE network simulator
Smart Grid Optimization Applying MARL to control power flow in an electrical power grid with optimum efficiency. Riedmiller, Martin, Andrew Moore, and Jeff Schneider. “Reinforcement learning for cooperating and communicating reactive agents in electrical power grids.” Workshop on Balancing Reactivity and Social Deliberation in Multi-Agent Systems. Springer, Berlin, Heidelberg. 2000.(23회 인용)
Smart Cross Light Applying MARL to control traffic lights to minimise wait time for each car in a city, making them more adaptable based estimates of expected wait time. Wiering, M. A. “Multi-agent reinforcement learning for traffic light control.” ICML, 2000.(362회 인용)
{kind=link}
- Multi-Agent Deep Reinforcement Learning for Large-scale Traffic Signal Control
- IEEE Transactions on Intelligent Transportation Systems (2019)
- The multi-agent RL (MARL) overcomes the scalability issue by distributing the global control to each local RL agent, but it introduces new challenges
- actor critic(A2C) architecture
- This paper presents, for the first time, a fully scalable and decentralized MARL algorithm for the state-of-the-art deep RL agent, advantage actor critic (A2C), within the context of ATSC.
- 24회 인용
- Economics
- Pricing in Agent Economies Using Multi-Agent Q-Learning
- we study simultaneous Q-learning by two competing seller agents in three moderately realistic economic models. This is the simplest case in which interesting multi-agent phenomena can occur, and the state space is small enough so that lookup tables can be used to represent the Q-functions.
In one of the models (the “Shopbot” model) where the sellers’ profit functions are symmetric, we find that Q-learning can produce either symmetric or broken-symmetry policies, depending on the discount parameter and on initial conditions.
- Tesauro, Gerald, and Jeffrey O. Kephart. “Pricing in agent economies using multi-agent Q-learning.” Autonomous Agents and Multi-Agent Systems 5.3 (2002): 289-304.
- 156회 인용
- 응용 사례
{kind=link}
Unity with OpenAI Gym
유니티는 ML 에이전트 툴킷을 처음 출시할 당시 학습 환경과의 상호작용을 위해 커스텀 Python API를 제공했습니다.
관찰 공간이 복잡하게 섞여 있는 환경에서 멀티 에이전트와 멀티 브레인 학습을 수행하는 시나리오를 사용할 수 있게 되었습니다.
이제 Unity 환경과의 상호작용에 사용할 수 있는 gym 인터페이스가 제작되었다는 기쁜 소식을 전해드립니다.
gym 사용에 관한 실험 파이프라인을 제작하는 연구자는 이제 다른 gym 환경을 손쉽게 Unity gym 환경으로 바꿀 수 있습니다. gym 인터페이스에 대한 자세한 내용은 Unity의 패키지 페이지(영문)를 참조하세요.
2019년 5월 2일 기준으로 베타 버전을 발표한 상태
ML-agent를 학습할 수 있는 4가지 방식 1) 강화학습
2) 모방학습(Imitation Learning)
3) neuroevolution
4) 그 외의 다른 알고리즘
현재 OpenAI Gym에서 mujoko 시뮬레이터가 유료화 되고 리눅스 환경에서만 사용할 수 있는 반면, 유니티 환경에서는 무료인 동시에 윈도우에서도 사용이 가능하다.
- ML-agent의 특징
- Python으로 Control되는 Unity 환경
- 10개 이상의 샘플 환경(Example)
- 다양한 환경설정 값과, 훈련 시나리오
- memory-enhanced Deep reinforcement learning(메모리 활용 심층 강화학습)
- 쉽게 정의할 수 있는 커리큘럼 Learning 시나리오
- 내장 되어있는 모방학습
- 유연한 컨트롤 with on-demand decision making.
- 네트워크 출력의 시각화
- 쉬운 도커 셋업
- 학습환경을 gym이라는 것으로 추상화
- 유니티의 추론 엔진을 사용
- 여러개들 동시에 학습
- OpenAI Gym MuJoCo : https://www.roboti.us/license.html
Game : Starcraft
- AlphaStar(DeepMind) : 2019년 상위 0.2% 실력 달성
- 동일 종족만 상대가 가능하여 프로토스 대 프로토스 경기만 했다. 하지만, 지난 10월에는 알파스타가 멀티 에이전트 강화 학습으로 스타크래프트 모든 종족에서 그랜드마스터 레벨에 도달했다. 알파스타는 사람과 비슷한 수준의 시야 정보 및 명령속도(APM)를 가진 상태로 스타크래프트 공식 게임 서버인 배틀넷에서 게임에 임했다.
- Alibaba and University of London : 2017년 발표
- Researchers from Alibaba and UCL set the multi-agent StarCraft combat mission to zero and random. Different agents communicate with each other through a new bi-directional coordination network (BiCNet), and learning is done through an evaluation-decision-making process. In addition, researchers also proposed the idea of sharing parameters and dynamic grouping to solve the problem of scalability.
To maintain a scalable yet effective communication protocol, we introduce Multi-agent BidirectionallyCoordinated Network (BiCNet [’bIknet]) with a vectorised extension of actor-critic formulation.
BiCNet : BiCNet is a multi-agent enhanced learning framework that utilizes bidirectional neural networks. It constructs a vectorized assessment-decision approach, where each dimension corresponds to an agent. The coordination between agents is done through a two-way internal communication. Through end-to-end learning, BiCNet can successfully learn a variety of effective collaborative strategy. This study proves that the system can coordinate various arms in the real-time strategy game “StarCraft”, resulting in a variety of effective tactics. In the experiment, the researchers found that there was a strong correlation between the specified incentive and the learning strategy. They plan to further study the relationship, explore how agents communicate in the network, and whether they will generate a specific language. In addition, when both sides use a deep multi-agent model for the game, the study of the Nash equilibrium will also be a very interesting research topic.
- 삼성 SDS : AI 스타크래프트 도전기
- 동일 기종의 멀티에이전트 컨트롤을 목표로 모델 제작
- Actor-Critic Architecture를 채용한 대표적인 off policy Deep Deterministic Policy Gradient(DDPG) 모델 제작
- BiCNet 기반 Decentralized actor와 Centralized critic의 구조
- 유닛 개수에 따라 모델파라미터가 늘어나지 않도록 조정
- 글로벌 리워드를 추가하여 에이전트 간 협동을 가장 우선 순위로 둠 AC architecture
{kind=link}
{kind=link}
추가 참고 자료
ETRI 2019 심층강화학습 라이브러리 기술 동향 : https://ettrends.etri.re.kr/ettrends/180/0905180008/34-6_87-99.pdf
Why the multi agent system is hard? : https://medium.com/hackernoon/why-coding-multi-agent-systems-is-hard-2064e93e29bb
Reinforcement learning applications : https://arxiv.org/pdf/1908.06973.pdf
AAAI 2019 - A tutorial RL : https://outreach.didichuxing.com/tutorial/AAAI2019/
MADDPG 설명 : https://jay.tech.blog/2018/08/04/multi-agent-actor-critic-rl/
Introduction of MARL : http://www.dcsc.tudelft.nl/~bdeschutter/pub/rep/10_003.pdf
A Comprehensive Survey of MARL : https://ieeexplore.ieee.org/abstract/document/4445757 (586회 인용 / 2008)