[Paper Review] Grad-CAM
CNN Visualization
- Black Box 모델이라 속을 알 수 없는 CNN 모델이 과연 데이터를 얼마나 잘 설명하고 있고, 이렇게 설명한 이유에 대해 판단하는 근거를 찾기 위해 CNN Visualization은 CNN이 발전하면서 꾸준히 화자되어 왔다.
- 초창기 CNN Visualization은 1st Layer와 같이 앞 단의 계층에서 시각화 하여 보여졌다. 하지만, 앞 단의 CNN은 주로 low level feature 를 가지고 있기에 마치 영상처리에서 여러 방향 edge나 color를 찾는 기본적인 필터와 같은 형태를 보이고 있었다.
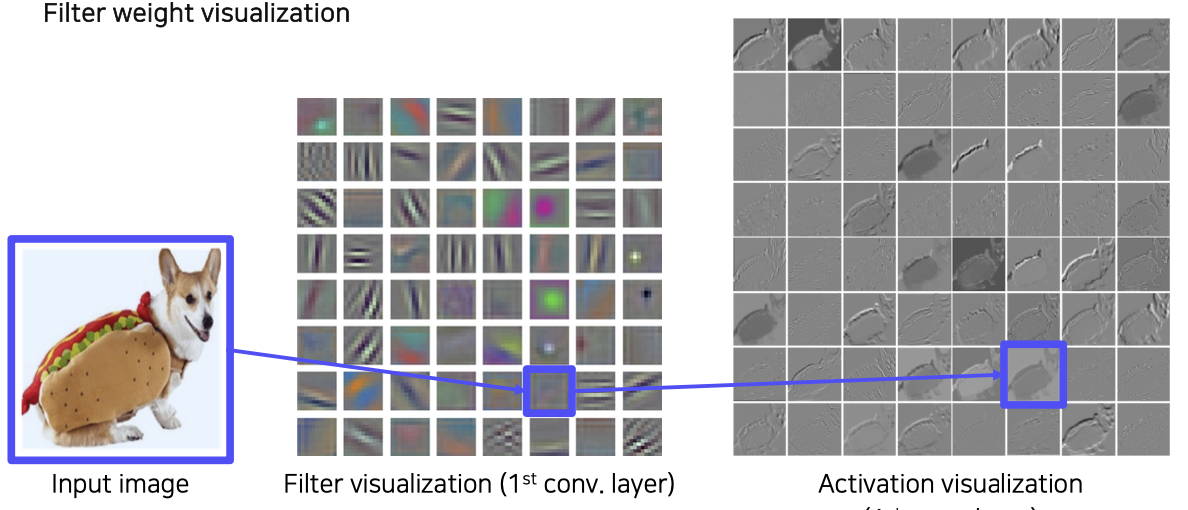
- Activation 단계에서 봐도 도통 CNN이 어떤 근거로 이를 돌고래로 판단하고 있는지 잘 보이지 않는 것을 볼 수 있다.
- 그렇다고 high level feature를 가지고 있는 뒷 단의 convolution layer를 볼 수 없었다. 이유는 채널 수가 이미 너무 늘어나 사람이 인식할 있는 범위를 넘었기 때문에 이를 시각화 하기엔 쉽지 않았다.
- 그래서 보통의 신경망 시각화들처럼 model에 초점을 맞추거나, 데이터에 초점을 맞추는 방법들이 보이고 있었다. 하지만, model에 집중하여 모델 파라미터 또는 feature를 분석하기엔 위에서 보았듯이 convolution filter의 feature들을 해석할 방법이 없었고, 모델 자체도 black box 모델이므로 불가능 했다.
- 그래서 데이터에 초점을 맞춰서 모델이 도출한 결과를 설명하는 방법론들이 우세하게 되었다. 이제 설명할 Grad-CAM은 Sensitivity analysis의 한 종류로 모델 output이 어떤 이유로 나왔는지를 설명해 준다. 같은 종류로는 Saliency map 등이 있고, 다른 방법으로는 Decomposition 방법 중 DeepLIFT, LRP 등이 있다.
CAM (Class Activation Map)
Global Average Pooling(GAP)
- Grad-CAM의 전신이 되는 모델로
Grad-CAM은 CAM을 일반화 시킨 모델이다. - CAM은 CNN 모델로 이미지 분류 문제를 다룰 때, 어떤 부분이 class에 큰 영향을 주었는지 확인 할 수 있는
importance weight를 처음으로 제안했다. 이는 마지막 layer의 convolution filter에 weight로 곱해져 어떤 채널의 filter가 output score에 더 큰 영향을 미쳤는지를 나타낸다.
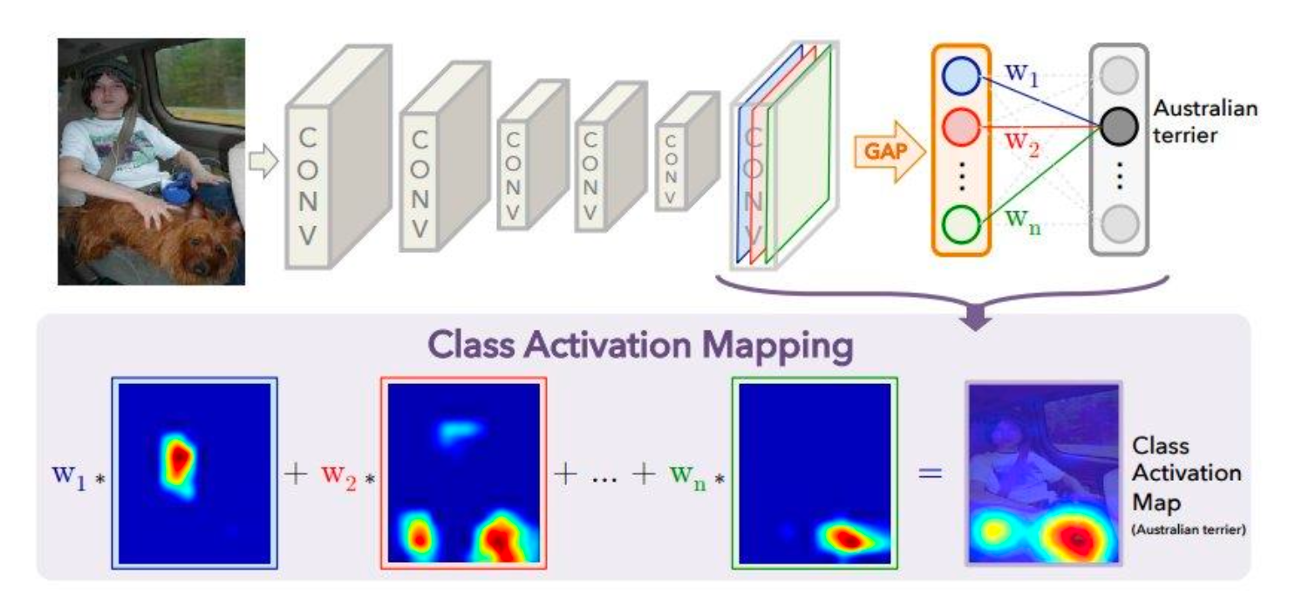
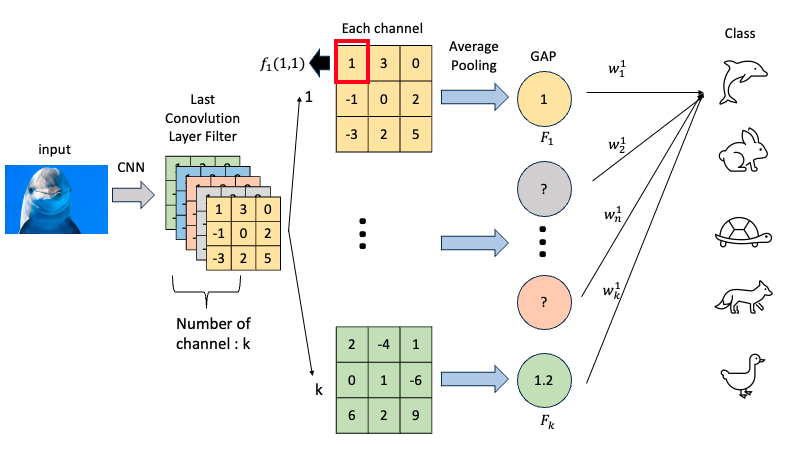
- 위의 구조에서 보면 가장 마지막 convolution layer에 담긴 high level feature 를
Global Average Pooling(GAP)로 요약하고 있는 것을 볼 수 있다. 각 채널 k의 x,y 좌표에 해당하는 값들을 모두 평균내는 GAP를 수식으로 표현하면 아래와 같다. (Z : 픽셀 개수)
- GAP는 앞서 2015년에 발표된 Weakly supervised learning with convolutional neural networks for power line localization 논문 에서 소개된 개념이다. 해당 논문에서는 Average 말고도 Max로 feature map의 정보를 요약하기도 했다. 하지만, 실험적으로 GMP보다는 GAP가 객체를 추출하는 localization 성능이 좋다는 것을 입증했다.
왜 마지막 convolution layer만 쓸까?
- CAM 방법은 이렇게 요약된 정보 \(F_k\)에
각 채널별로 학습가능한 importance weight를 따로 곱해주는 것이다. - 따라서 CAM을 적용하려면 모델의 가장 마지막 convolution 연산 이후 layer를 수정해야 한다. 이는 추후 Grad-CAM이 나오게 된 가장 큰 계기가 된다.
- 여기서 마지막 layer 정보로만 모델을 설명할 수 있는 가장 큰 이유는 가장 마지막 layer에서 바라보는 receptive field 가장 크기 때문에 정보량이 가장 많을 수 밖에 없기 때문이다. 쉽게 말해, 마지막 feature map 내 픽셀 1개 값은 원본 이미지에서 이미 많은 부분을 요약한 결과가 되기 때문이다.
Formula
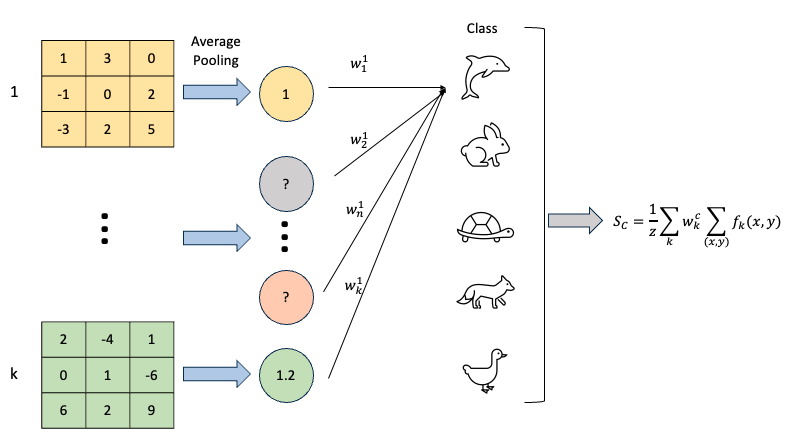
이제 위의 그림과 같이 CAM이 중요한 영역을 시각화하기 위해 GAP로 채널 정보들을 요약하고 weight로 영향력을 가중해준 것을 알 수 있다. 이렇게 영향력이 가중된 요약 정보들이 모여 “돌고래” 라는 클래스를 예측하는 것이다.
이에 대해 더 자세한 수식을 살펴보고 그 수식이 가지는 의미를 파악해보자.
- k : last convolution filter의 channel 번호
- c : output class
- \(S_c\) : 클래스 c에 대한 output score
- \(w^k_c\) : k개의 채널별 클래스 c GAP의 가중치
- \(F_k\) : 채널 k 번째 GAP
이 수식은 k 번째 채널의 GAP에 importance weight를 곱해주어, 각 클래스 c에 대한 output score를 구한 간단한 수식이다. 쉽게 말하면, 각 클래스 별로 k개의 채널별 feature map들에 중요도를 곱하고 전부 더한 점수를 나타낸 것이다. 이는 CAM에서 class score를 정의하는 수식이다. 이어서 \(F_k\) 를 각 픽셀에 대해 나눠서 생각해보자.
\[S_c = \sum_k w_k^c \sum_{(x,y)} f_k(x,y) \cdot\cdot\cdot (1)\] \[= \sum_{(x,y)} \sum_k w_k^c f_k(x,y) \cdot\cdot\cdot (2)\] \[CAM_c(x,y) = \sum_k w_k^c f_k(x,y) \cdot\cdot\cdot (3)\]수식 (1)에서 \(F_k\)를 픽셀 위치별로 나누어 \(f_k\) 함수로 나타낸 것이다. 그리고 분배법칙에 의해 summation 순서를 바꿔주면, 수식 (2)와 같이 된다.
최종적으로 수식 (3)을 살펴보면 픽셀별로 모든 채널 k에 대해 weighted sum을 한 결과임을 알 수 있다. 이를 쉽게 해석해보면, 수식 (3)은 모든 채널에 대한 값을 모았기 때문에 클래스 c에서 x, y 위치 픽셀의 영향력이라 볼 수 있다. 이를 Activation Value라 한다.
Summary
- CAM은 이미지 분류를 하면서 해당 클래스로 분류된 이유를 시각화 해주는 방법론으로, 시각화를 하면서 객체의 위치를 bounding box와 같은 학습데이터로 주지 않아도 어느 정도 위치를 찾을 수 있다.
- 이는 모델의 마지막 convolution layer 이후 구조를 변경하여 앞서 제안된 GAP 개념과 weight importance을 도입하여 각 픽셀들이 얼마나 output score에 영향력을 미치고 있는지 계산할 수 있다.
- 이를 히트맵으로 시각화 하여 보면 각 클래스에 대해 픽셀들이 얼마나 중요도를 가지는지 한 눈에 파악할 수 있다.

Grad-CAM (Gradient CAM)
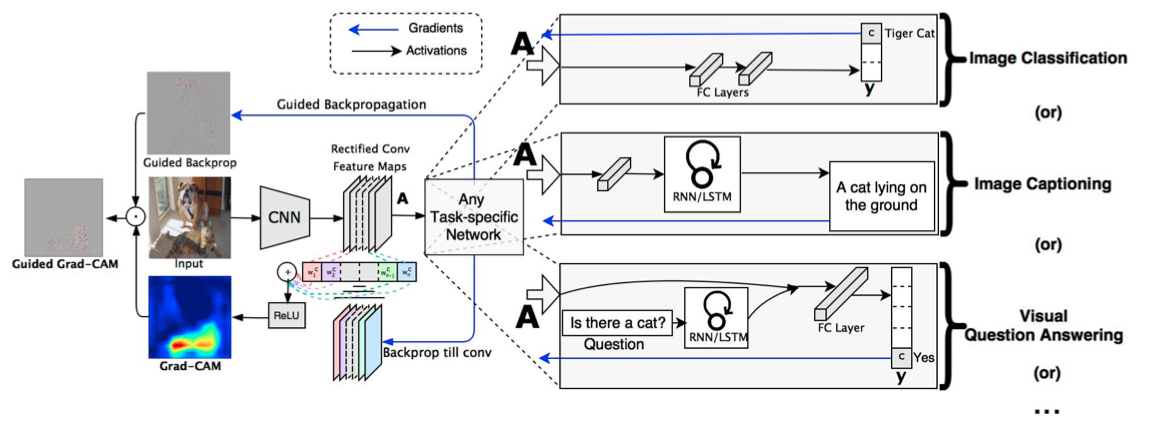
- Grad-CAM은 CAM이 모델 구조를 변경해야 하므로 CNN을 feature extraction으로 사용하고 RNN이나 LSTM을 사용하여 그림을 설명하는 Image Captioning 이나 VQA 같은 문제에 적용되지 못하는 한계점을 극복하고 일반적인 CAM 방법을 제안한다.
- GAP대신 마지막 convolution filter 내 각 픽셀 위치들이 해당 클래스를 판단하는데 얼마나 영향력을 미쳤는지를 계산하기 위해 Gradient를 사용한다. 즉, 학습가능한 weight 대신 back-propagation 한 번으로 gradient를 계산하여 대체한다.
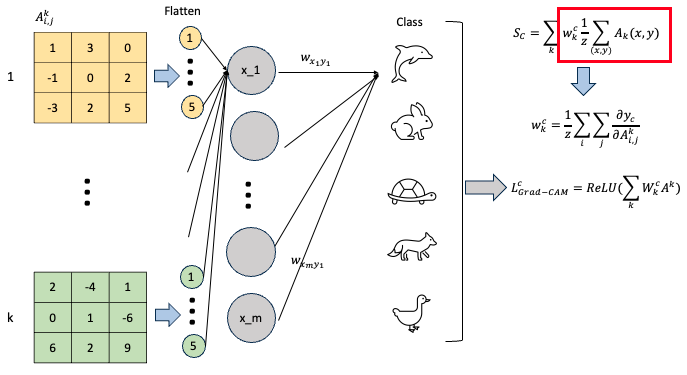
Formula
- 위에서 간략하게
This post is licensed under CC BY 4.0 by the author.